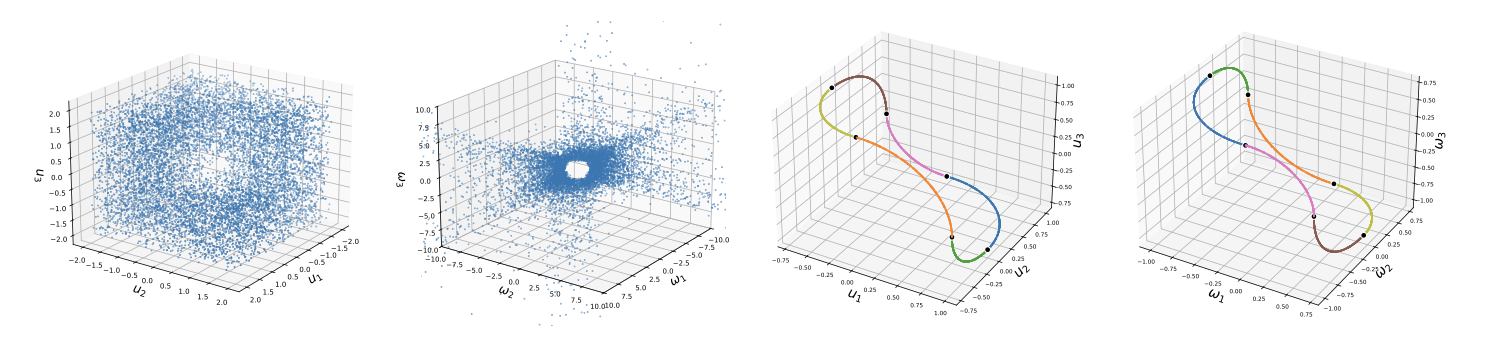
Effects of l2-regularization and hyperparameters on loss landscape
In this report, we aim to explain the characterization of distinctive learning behaviors of two-layer ReLU neural networks depending on hyperparameters from a viewpoint of their loss landscape. For the first part of this work, we focus on a two-layer ReLU with one-dimensional data and then characterize the set of globally optimal parameters analytically. We analyze them with or without l2-regularization so that we can see the effects of the regularization. Based on the relationships between their geometrical properties and the locations of the initial parameters, we separate the hyperparameter space. Our separation provides a possible explanation for the distinctive dynamical behaviors of two-layer ReLU networks minimizing squared loss, which are often analyzed at the infinite-width limit.
The report is available at link to pdf.
Below is the illustration for the set of globally optimal parameters in the parameter space.